E Ferrara, M JafariAsbagh, O Varol, V Qazvinian, F Menczer, and A Flammini.
2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM’13), 2013.
The increasing pervasiveness of social media creates new opportunities to study human social behavior, while challenging our capability to analyze their massive data streams. One of the emerging tasks is to distinguish between different kinds of activities, for example engineered misinformation campaigns versus spontaneous communication.
Such detection problems require a formal definition of meme, or unit of information that can spread from person to person through the social network. Once a meme is identified, supervised learning methods can be applied to classify different types of communication. The appropriate granularity of a meme, however, is hardly captured from existing entities such as tags and keywords.
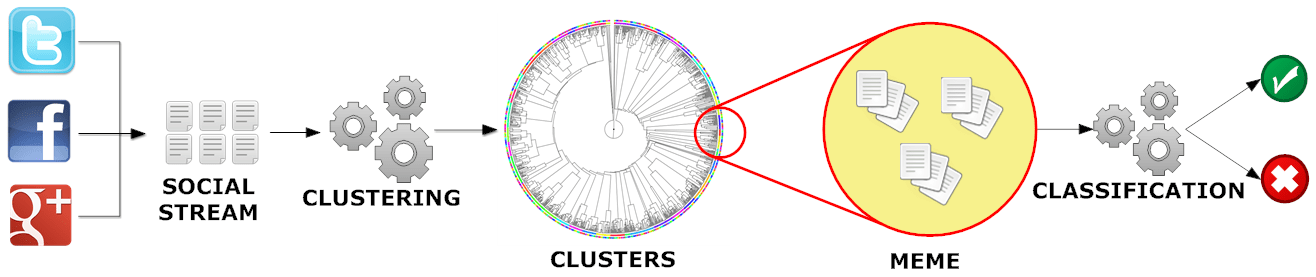
Here we present a framework for the novel task of detecting memes by clustering messages from large streams of social data. We evaluate various similarity measures that leverage content, metadata, network features, and their combinations. We also explore the idea of pre-clustering on the basis of existing entities. A systematic evaluation is carried out using a manually curated dataset as ground truth.
Our analysis shows that pre-clustering and a combination of heterogeneous features yield the best trade-off between number of clusters and their quality, demonstrating that a simple combination based on pairwise maximization of similarity is as effective as a non-trivial optimization of parameters. Our approach is fully automatic, unsupervised, and scalable for real-time detection of memes in streaming data.